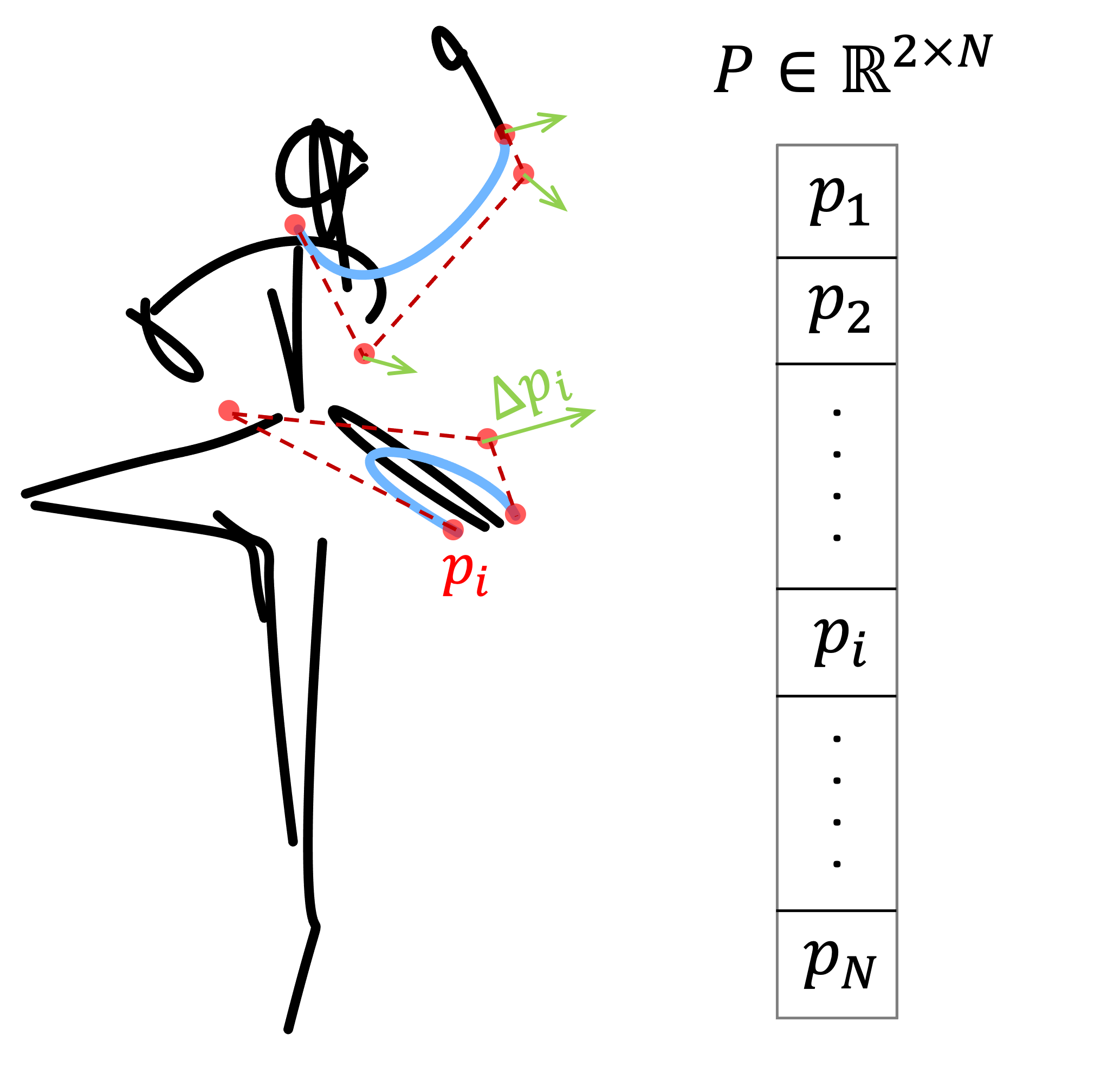
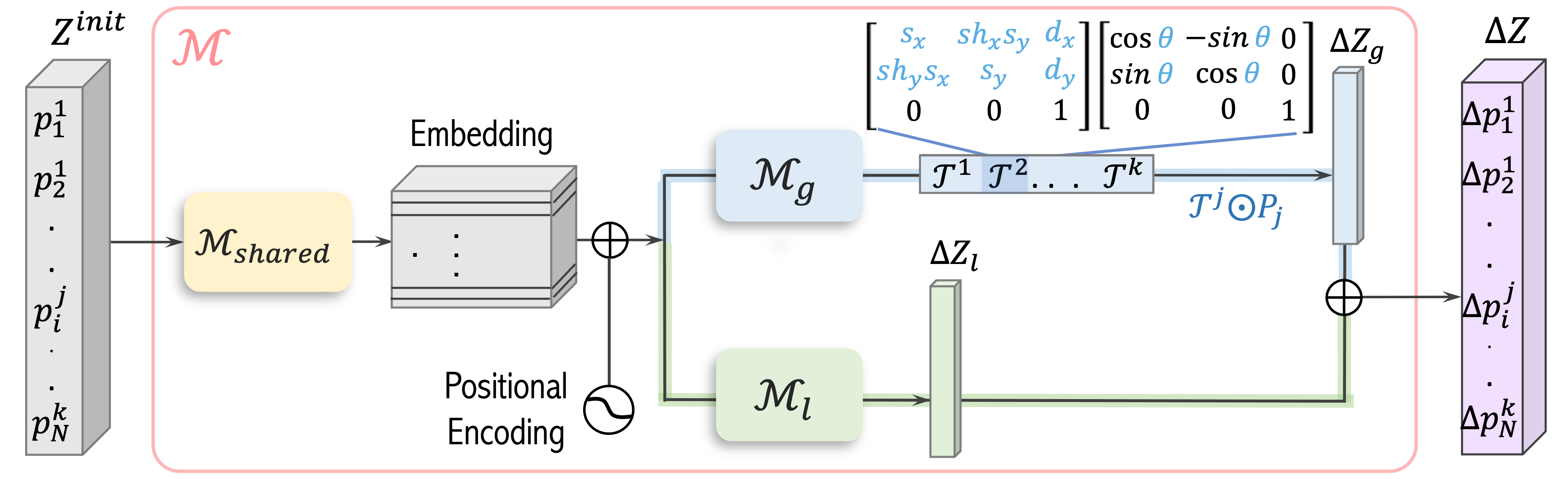
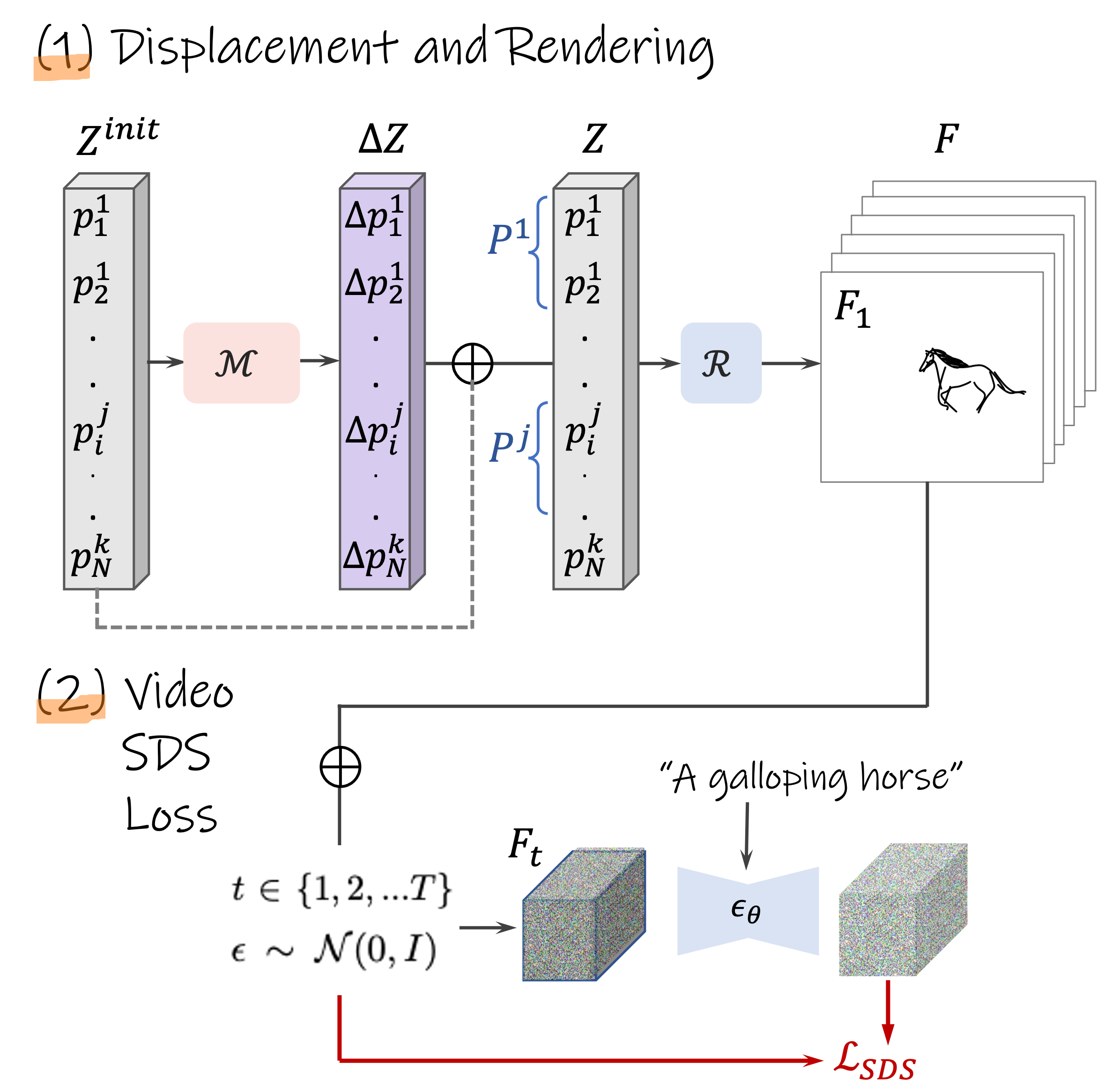
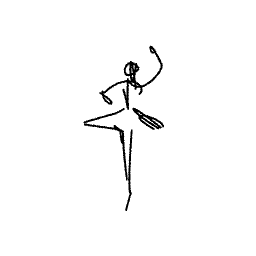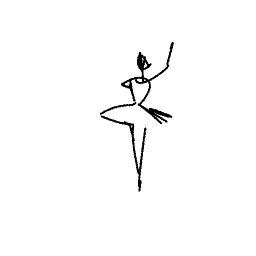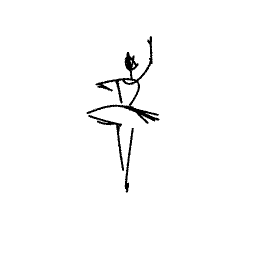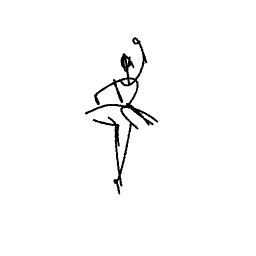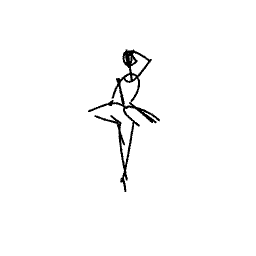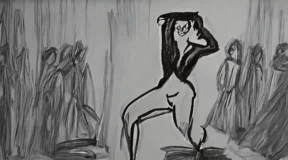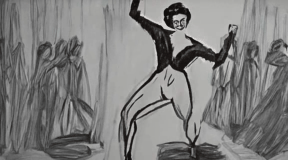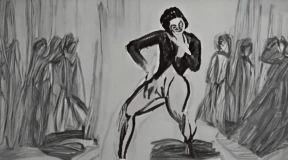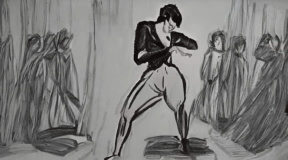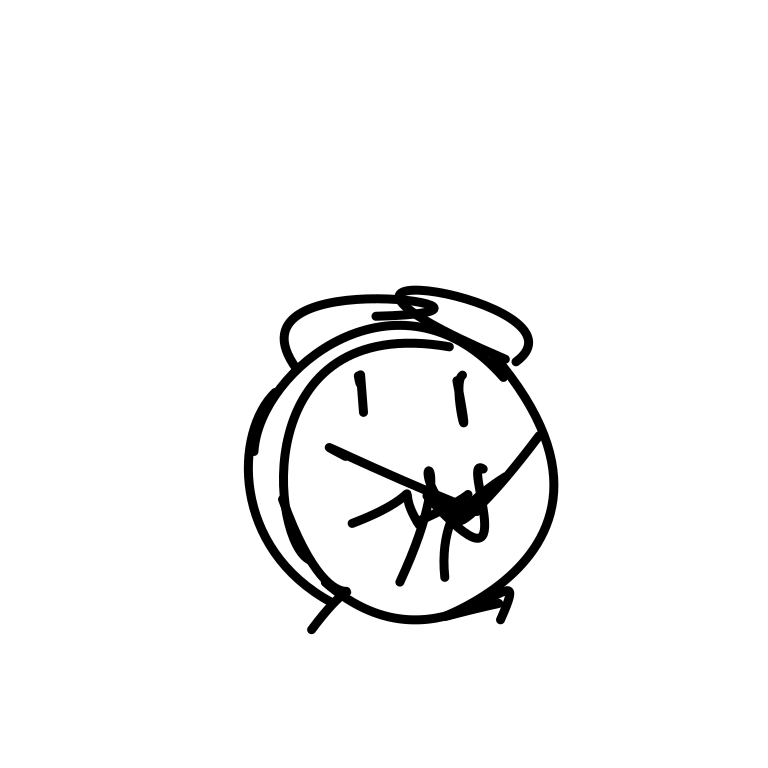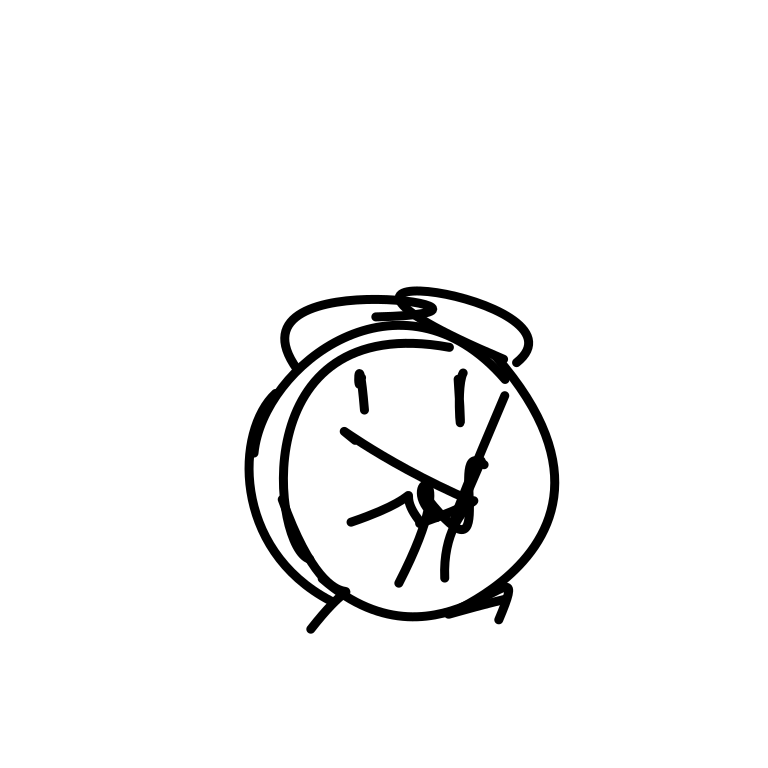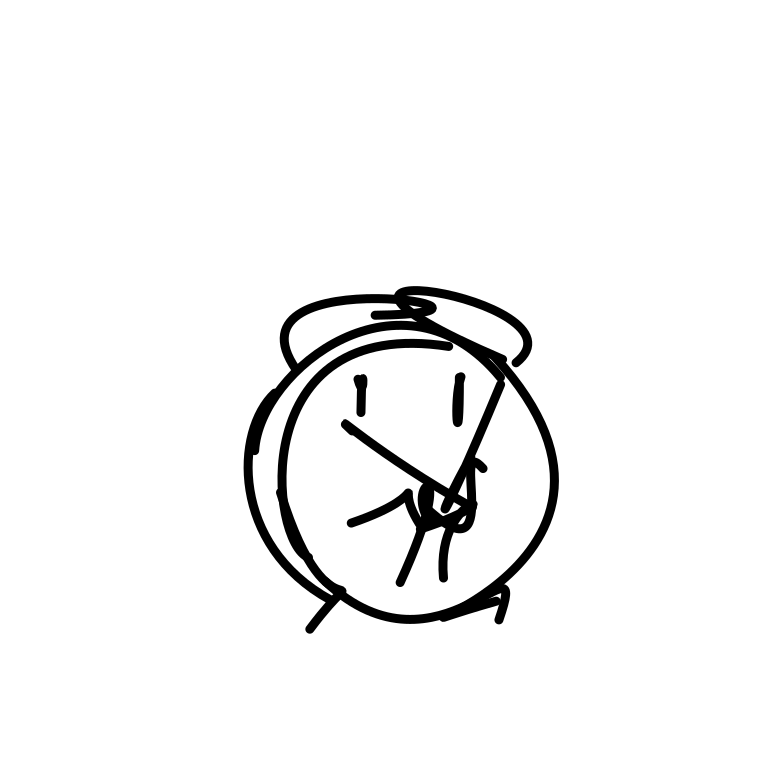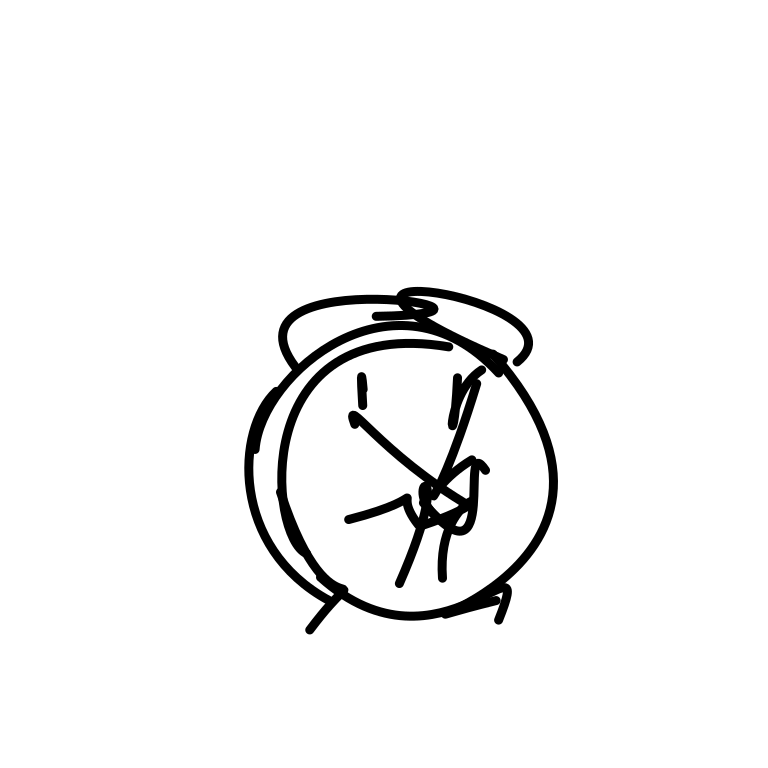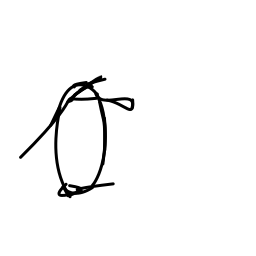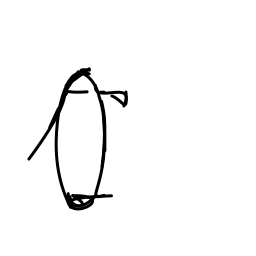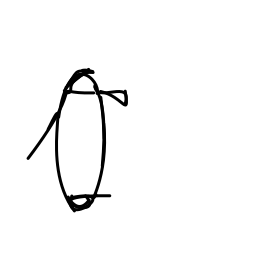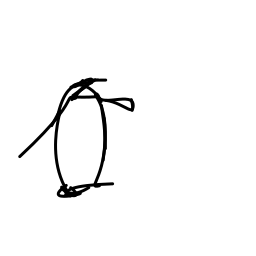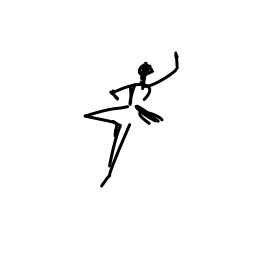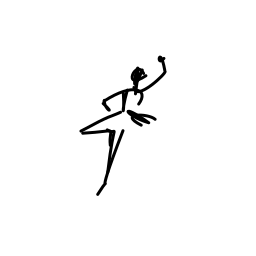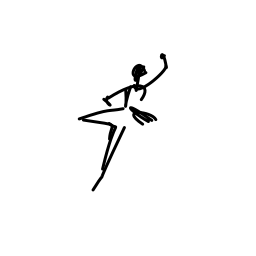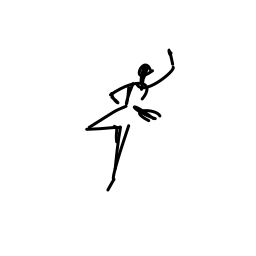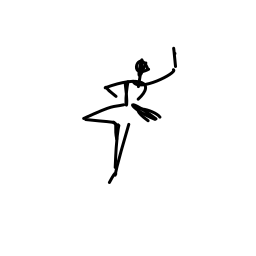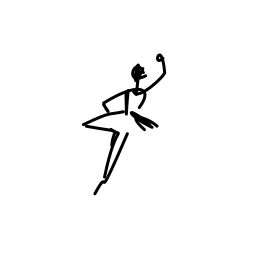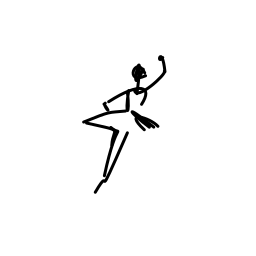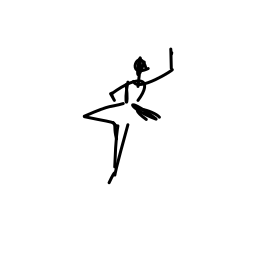Gallery


A dolphin swimming and leaping [..]
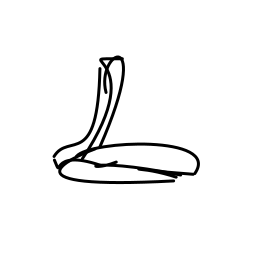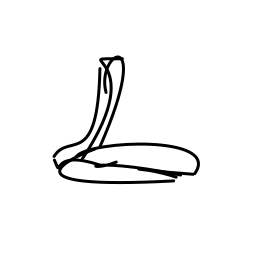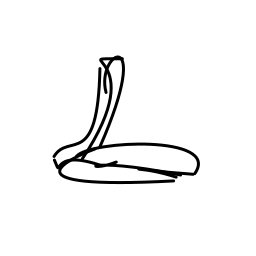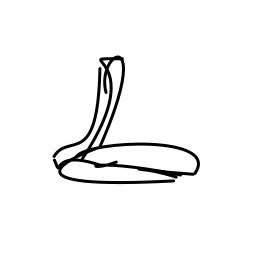
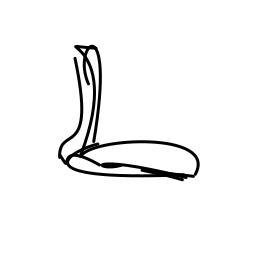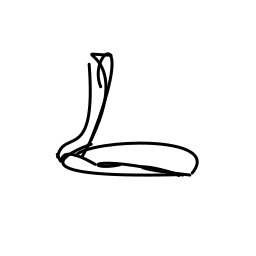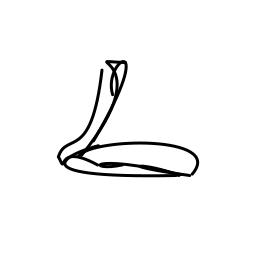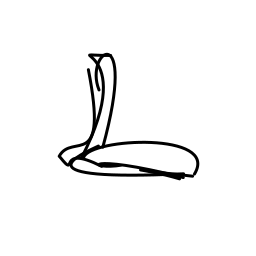
The hypnotized cobra snake swa [..]


The cat is playing. [..]


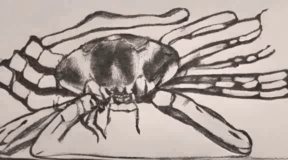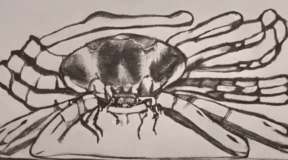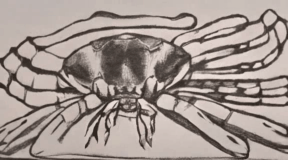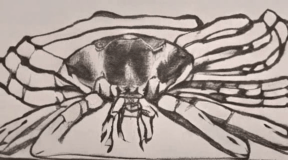
The crab scuttled sideways alo [..]


The flower is moving and growing [..]


The penguin is shuffling along [..]

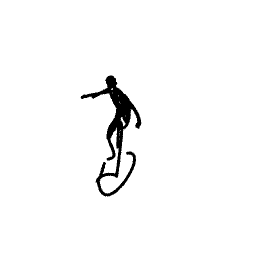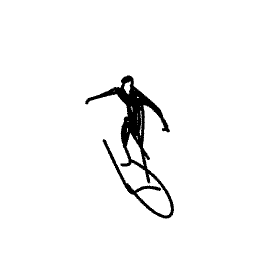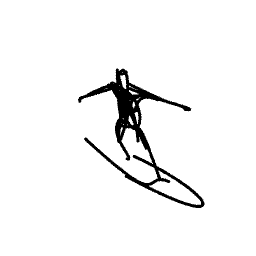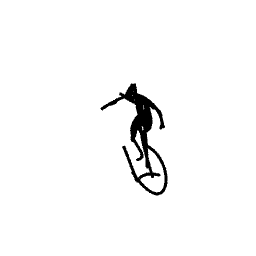
A surfer riding and maneuvering [..]


The runner runs with rhythmic [..]


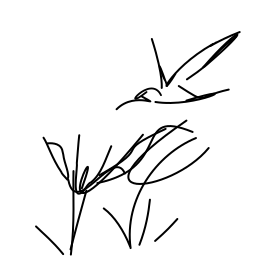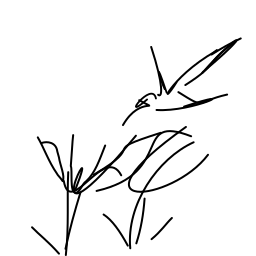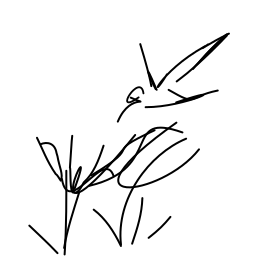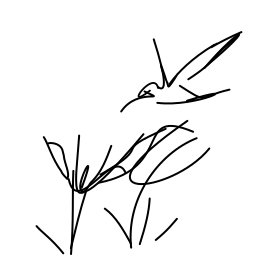
A hummingbird hovers in mid-ai [..]


The lizard moves with a sinuou [..]


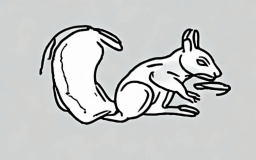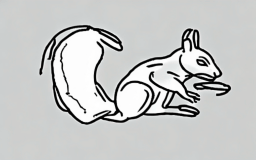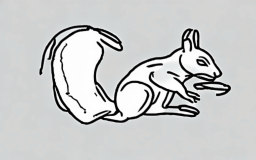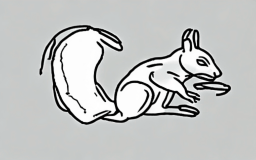
The squirrel uses its dexterou [..]


A hummingbird hovers in mid-ai [..]


A butterfly fluttering its win [..]


A dolphin swimming and leaping [..]


A gazelle galloping and jumpin [..]


The squirrel uses its dexterou [..]


The cat is playing. [..]


The eagle soars majestically, [..]


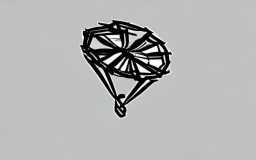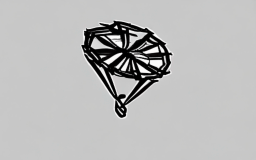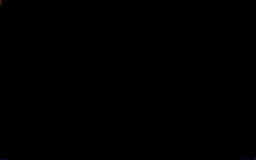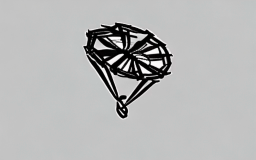
A parachute descending slowly [..]


The flower is moving and growi [..]


A butterfly fluttering its win [..]


A gazelle galloping and jumpin [..]
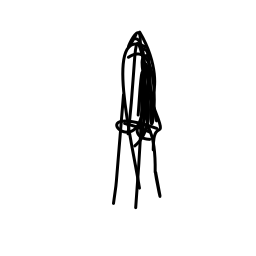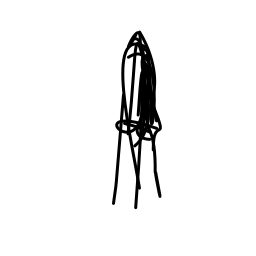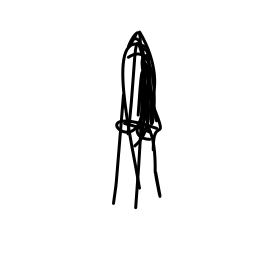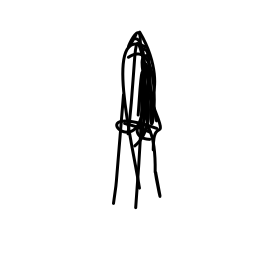

The spaceship accelerates rapi [..]


The cat is playing. [..]

The ballerina is dancing. [..]


A ceiling fan rotating blades [..]
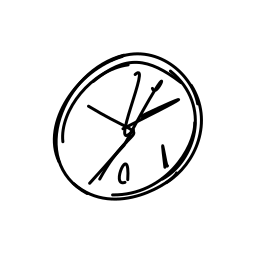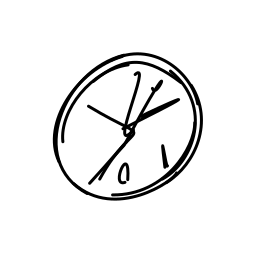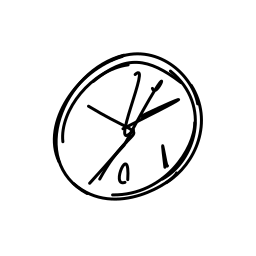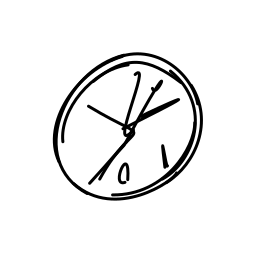
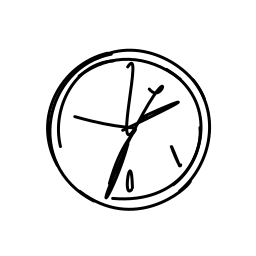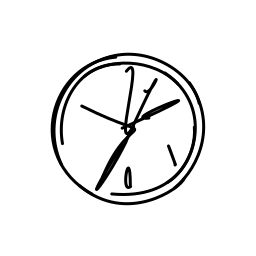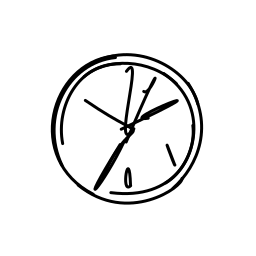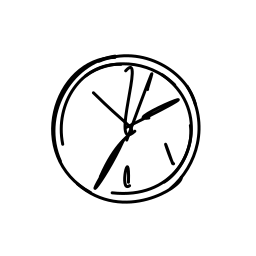
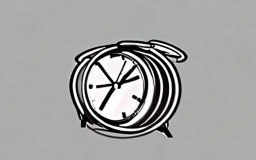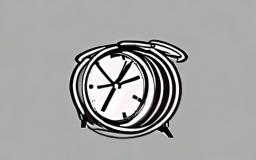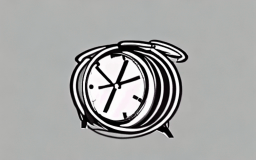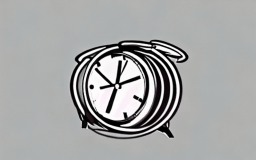
A clock hands ticking and rota [..]
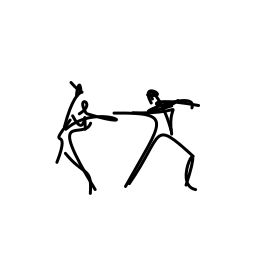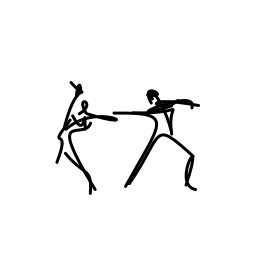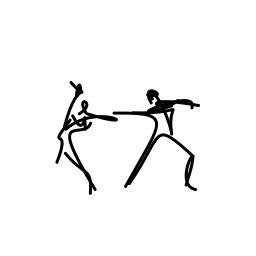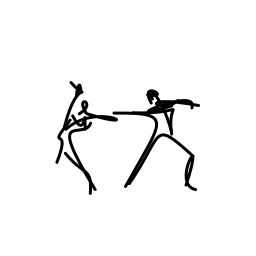

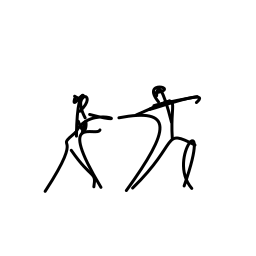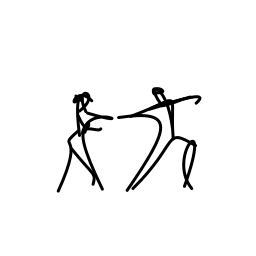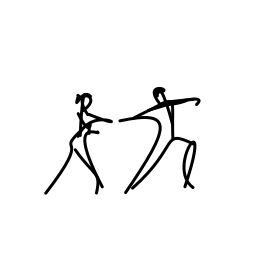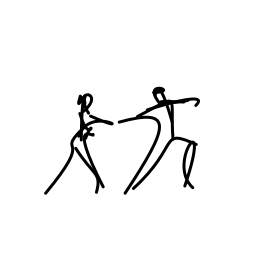
The two dancers are passionate [..]


The goldenfish is gracefully m [..]
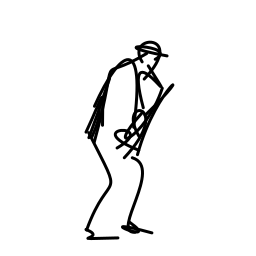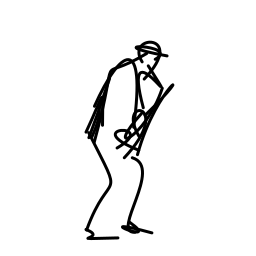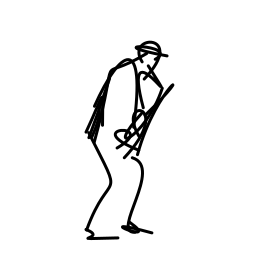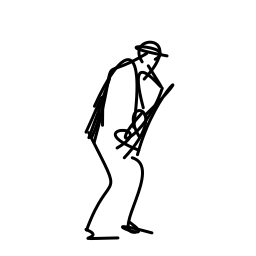

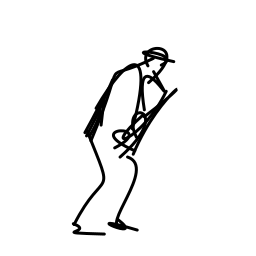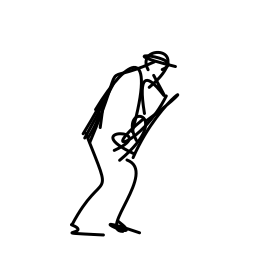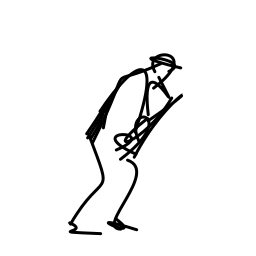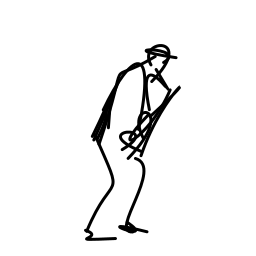
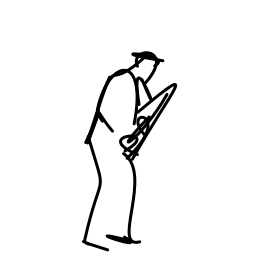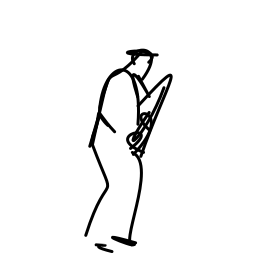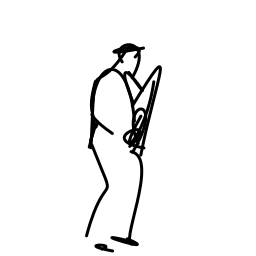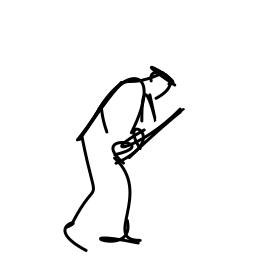
The jazz saxophonist performs [..]


A galloping horse. [..]


The wine in the wine glass swa [..]


The squirrel uses its dexterou [..]


A basketball player dribbling [..]


The biker is pedaling, each le [..]


A waving flag fluttering and r [..]


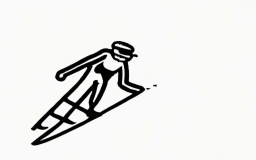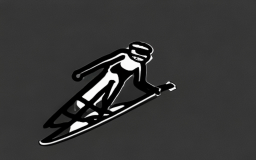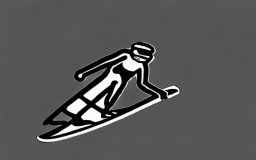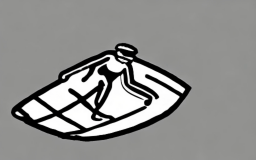
The man sailing the boat, his [..]
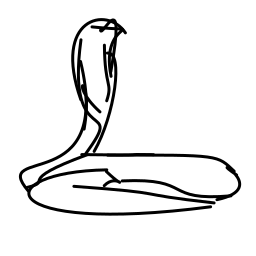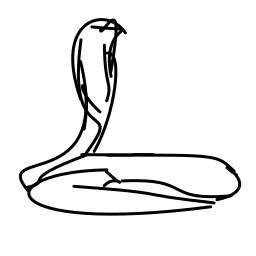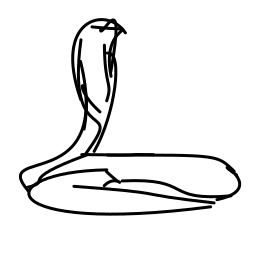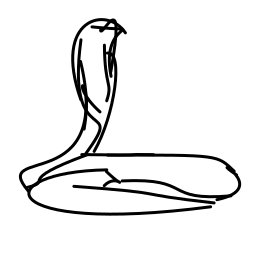

The hypnotized cobra snake swa [..]

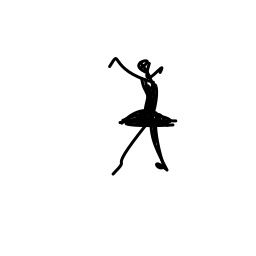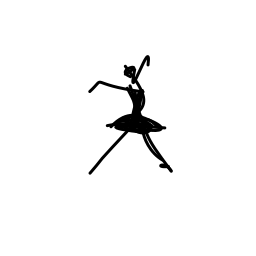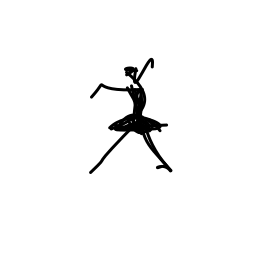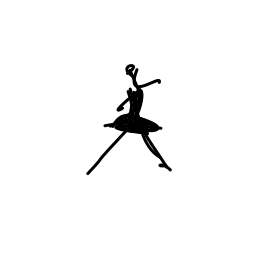
The ballerina is dancing. [..]

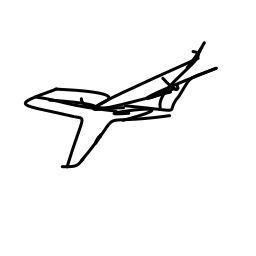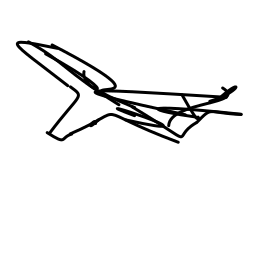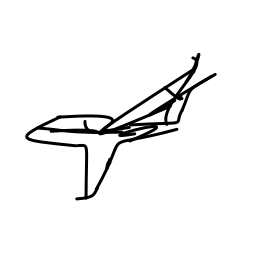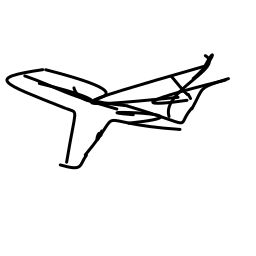
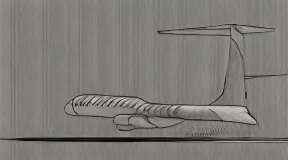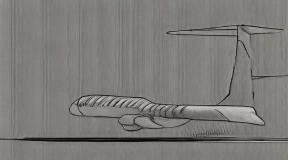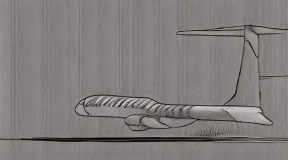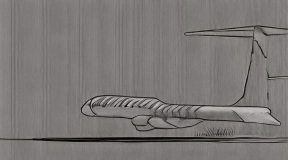
The airplane moves swiftly and [..]

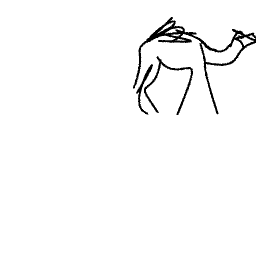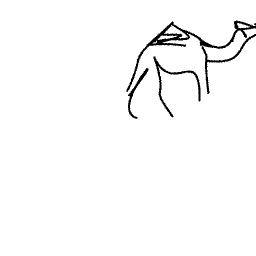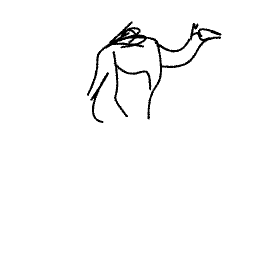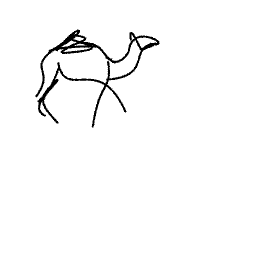
A camel is walking